
17 juin 2015, Google publie sur son blog de recherche un article aux images étranges : on y découvre les « rêves » psychédéliques « imaginés » par des ordinateurs.

Derrière ces images, une famille d’algorithmes au nom évocateur : le deep learning. Depuis, a peu près tous les journaux, même généralistes, en ont parlé, du Monde à Wired en passant par la dépêche du midi, tous s’interrogent sur ce mystérieux « apprentissage profond ».
Certains et pas des moindres tel Hawkins ou Musk y voient même les prémisses de l’intelligence artificielle et donc un danger pour l’homme!
Il était donc temps pour Podcast Science de faire le point. Commençons d’abord par le deep learning avant de se poser la question de l’avenir de l’humain dans un prochain dossier.
Apprendre
Le deep learning est un nouveau nom pour des algorithmes d’apprentissage ou encore « Machine Learning » en anglais. Le machine learning est une manière bien particulière de résoudre des problèmes. Alors que la plupart des scientifiques cherchent à modéliser un phénomène pour prédire des effets, ceux qui font de l’apprentissage cherchent à créer la machine la plus à même à résoudre le problème toute seule. Ils conçoivent leur machine de manière à ce qu’elle ait tout un tas de paramètre à régler pour s’adapter au problème, c’est ce qui lui permet d' »apprendre ».
Cette formulation est trompeuse car pour la plupart des algorithmes d’apprentissage et en particulier pour le deep learning, la machine n’apprend pas vraiment au sens où l’on l’entend dans le langage courant, c’est beaucoup plus brutal et tristement mathématique. Imaginez que vous vouliez que votre machine « apprenne » à reconnaitre les membres de Podcast Science sur des photos. Vous allez devoir créer un ensemble d’images d’exemple, sur lesquelles vous savez qui est présent pour lui permettre de s’entrainer.
Pour apprendre sur ce type d’algorithme, il va d’abord falloir quantifier ce qu’est un bon ou mauvais résultat sur l’ensemble d’apprentissage. Par exemple on pourra compter le nombre d’erreurs de jugement : Non ce n’est pas Robin, c’est Julie! L’apprentissage de la machine va alors consister à trouver les réglages de la machine qui va minimiser ce nombre d’erreur. Une fois que c’est fait, l’algorithme est figé et ne bougera plus. A chaque fois que vous lui présenterez la même photo, il présentera la même réponse, si un nouveau membre arrive dans le podcast, il n’apprendra jamais à le reconnaitre tout seul, il faudra reprendre la phase d’apprentissage.
Apprendre pour une machine, c’est donc résoudre un problème d’optimisation. C’est à dire trouver la meilleure solution à un problème donné sous certaines contraintes. Il existe deux grandes familles d’apprentissage :
- Le supervisé où l’on demande à l’algorithme de choisir parmi un ensemble de réponses déjà connues (trouver un des membres du podcast sur une photo).
- Le non-supervisé où l’on ne lui donne pas les classification mais un lui demande de les trouver. Dans la pratique, la différence est qu’au lieu de compter les erreurs, on va faire attention à ce que les différents groupes que propose l’algorithme soient cohérents (encore faut-il définir « cohérent ». Cela peut paraitre un détail mais dans tous ces algorithmes ce sont bien ces définitions de « juste », « pas juste », « cohérent » qui déterminent la solution trouvée.
Si ses partisans et utilisateurs essaient d’en faire un grand tout général, Le deep learning appartient en fait (dans la plupart des cas) à la famille de l’apprentissage supervisé pour un type bien précis d’algorithmes : le réseau de neurone artificiel.
Des neurones artificiels
Comme son nom l’indique, le réseau de neurone artificiel s’inspire des « vrais » neurones. Loin d’être un spécialiste en fonctionnement des vrais neurones, je vais me contenter de ces répliques artificielles plus ou moins réalistes. Le neurone artificiel est une étape de décision. C’est a dire qu’il prend un grand nombre de valeurs en entrée (par exemple les intensités des pixels d’une image) et combine ces valeurs pour dire oui ou non, c’est à dire pour accepter de transmettre l’information ou non à la suite du réseau.
Je pourrais m’arrêter là en vous disant que c’est compliqué d’entrer dans les détails mais en fait les neurones artificiels sont étonnement simples. Ils fonctionnent comme la plupart des examens! En entrée on a nos notes : 18 en maths, 3 en espagnol et 10 sport. Le réseau va alors combiner ces notes avec un certain coefficient : coefficient 10 en math, 3 en espagnol et 2 en sport ce qui donne un total de 
Dans tous les réseaux de neurones la logique est grosso-modo la même : on commence par additionner les valeurs à l’entrée du neurone en y affectant un poids plus ou moins important. Puis, on compare ce résultat à une autre valeur, si la somme est plus grande que ce seuil, cela peut passer à la suite, sinon, ça ne passe pas, le résultat est zéro.
Il y a donc, pour un seul neurone, plein de paramètres à ajuster :
- les poids affectés à chacune des entrées
- La valeur de seuil
Le neurone est donc capable d' »apprendre » en adaptant ces paramètres tout comme si j’adapte les coefficients de mon examen, je réussirai ou non!
Des couches de neurones
Dans la pratique, on ne travaille jamais avec un seul neurone mais avec un très grand nombre : les algorithmes les plus performants d’aujourd’hui font intervenir autant de neurones que dans une abeille et autant de connexion entre les neurones que dans le cerveau d’un chat!
Dans les réseaux de neurones artificiels, ces neurones sont organisés par couche. C’est à dire que l’on fait une couche de neurone et on relie toutes les sorties des neurones d’une couche avec tous les neurones de la couche suivante. Le nombre de connexion explose (et donc de paramètre, rappelez vous, ce sont les poids affectés aux entrées)!
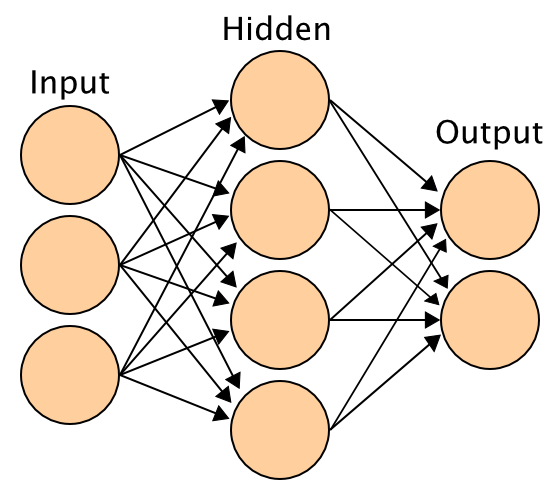
Un réseau de neurone artificiel
Imaginons par exemple que l’on a 3 valeurs d’entrées et 2 sorties possibles. Si l’on a un seul neurone entre les entrées et les sorties, il y aura donc 8 paramètres à régler : les 3 poids des entrées, le seuil pour la sortie du neurone, les deux poids d’entrées des deux sorties et les seuils de chacune des sorties. Si on ajoute un neurone dans la couche intermédiaire, on ajoute 6 paramètres, on passe alors à 14 paramètres et on n’est qu’à deux neurones intermédiaires! Dans l’image ci-dessus on a 4 neurones intermédiaires ce qui nous amène à 32 paramètres à régler!
Nouveau?
Voila un peu quelques bases de la « révolution » du deep learning. Mais est-ce que c’est vraiment révolutionnaire comme ont essayé de nous le faire croire plusieurs articles grand public? En fait, pas tellement, les réseaux de neurones sont apparus autour des années 50 et ont a plusieurs reprises été à la mode puis passés de mode. Le deep learning est en fait la 3e phase de « mode » des réseaux de neurones.
Les premiers réseaux de neurones étaient simpliste et ne faisaient pas vraiment intervenir des couches et sont assez vite passés de mode car ils étaient trop limités et d’autres approches se montraient plus efficaces. Dans les années 80, un nouveau regain d’intérêt avec des avancées qui ont posés la plupart des concepts des réseaux de neurones utilisés aujourd’hui. En particulier c’est l’apparition d’un algorithme rapide pour entrainer ces réseaux. Le deuxième déclin des réseaux de neurones a été amené par une déception dans ses résultats et l’apparition de nouveaux concepts de machine learning beaucoup plus efficaces.
Comment régler autant de paramètres.
Nous sommes donc, depuis la moitié des années 2000 dans la troisième vague des réseaux de neurones et contrairement à ce qu’on pourrait croire, la nouveauté ne se situe pas vraiment dans la technique.
Pour comprendre ce qui explique ce regain d’intérêt, je vous conseille l’excellente vidéo TED de Fei-Fei Li sur la reconnaissance d’images.
Dans cette vidéo, elle parle d’un réseau 24 millions de neurones pour un total de 14 milliards de connexions et au final 140 millions de paramètres (vous remarquerez qu’il y a largement moins de paramètres que de connexions, c’est parce que les réseaux actuels utilises des couches de neurones spéciales où certains paramètres sont partagés entre les connexions, pour permettre par exemple de traiter tous les endroits d’une image pareils).
La troisième vague des réseaux de neurones c’est l’échelle des réseaux et l’incroyable efficacité de certains algorithmes.
Vous donnez une image quelconque à l’algorithme de Fei-Fei et il vous décrit ce qu’il y a sur l’image. Si vous aviez demandé à n’importe quel chercheur en traitement d’images il y a quelques années, il vous aurait dit qu’on était très loin de ce genre de résultats…
Le deep learning donc, ce sont, comme son nom l’indique, des réseaux de neurones plus profonds, avec plus de couches de neurones, avec plus de neurones, avec plus de connexions.
Mais alors, c’est tout? Il suffisait d’augmenter le nombre de neurones pour que cela marche? Oui et non.
Imaginez que vous avez sous les main une machine, certes géniale, mais avec 140 millions de boutons à régler, vous avez l’impression d’avoir résolu le problème? Pas vraiment non, il reste à régler cette machine et c’est pas une mince affaire.
D’abord, il faut construire un ensemble d’images sur lesquelles vous allez tester et étalonner la machine. Vous vous doutez bien qu’avec 140 millions de paramètres, vous ne pouvez pas vous contenter de quelques milliers d’images, l’équipe de Fei-Fei Li a travaillé sur 15 millions d’images. Aujourd’hui, avec Instagram, Facebook, Google Images, etc., construire une telle collection d’images paraît facile mais il y a 20 ans, dans les années 90 c’était pratiquement impensable.
Quand vous avez ces 15 millions d’images, vous n’avez pas fini, il vous faut encore les classifier. Comme c’est la collection qui va vous permettre d’apprendre, il faut dire à la machine ce qu’est chaque image. Par exemple dans cette vidéo, c’est dans 22000 catégories qu’ont été classées les images. Mais qui va faire le travail de classifier ces 15 millions d’images? On n’a pas d’algorithme pour cela, on essaie de le construire!
On n’a donc que l’humain et il y a 10 ans il était impensable de faire classer 15 millions d’images par des humains… Aujourd’hui, c’est possible et relativement simple, il existe des outils comme le Mechanical Turk d’Amazon qui permet de justement faire faire ce genre de tâches à des des milliers d’humains du monde entier. A certains moments, les équipes de Fei-Fei Li on fait travailler 50000 personnes depuis 167 pays en même temps à cette tâche.
Et bien sur, la capacité de calcul et en particulier la capacité de calcul distribué sur des bases de données gigantesques a explosé ces dernières années. Cela permet de faire ce genre d’entrainement en un temps acceptable.
Le deep learning n’est pas vraiment une révolution scientifique, c’est une révolution technique!
Comment l’ordinateur rêve
A la fin de cette première partie, je me dois de vous répondre au sujet d’ouverture : Comment les ordinateurs rêvent?
Je dois vous faire un aveu, je n’aime pas vraiment le machine learning pour une raison qui ouvre justement l’article du blog de recherche de Google sur son algorithme de rêve justement :
« Artificial Neural Networks have spurred remarkable recent progress in image classification and speech recognition. But even though these are very useful tools based on well-known mathematical methods, we actually understand surprisingly little of why certain models work and others don’t. »
On construit de gigantesque machines, qu’on optimise automatiquement et quand elles marchent (diablement bien), on se sent un peu bêtes, on ne comprend pas vraiment ce qui se passe. Alors bien sûr, pour les optimistes cela leur donne l’impression que ces machines vont pouvoir tout faire vu qu’on ne les a pas conçues pour faire quelque chose en particulier mais pour d’autres c’est très frustrant.
La science s’est développée en construisant des modèles pour comprendre le monde, le machine learning construit des machines à modéliser le monde et de ce fait élimine la compréhension.
Les « rêves » que vous avez pu voir sont une tentative de compréhension. Les ingénieurs de Google sont allés voir ce qui se passait dans les couches de neurones lorsqu’ils faisaient de la reconnaissance. Ils donnent donc une image à leur machine à décrire puis puis remontent sur une couche de neurones et dit à ces neurones « quoi que vous voyez, amplifiez le! » Les premières couchens voient alors des détails abstrait, des lignes, des coins, c’est ces rêves très géométriques que vous avez pu voir.
Quand on va dans les dernières couches, ce qui est reconnu est plus concrêt : ce sont ces yeux, ces têtes d’animaux, etc. qui apparaissent.
Si l’on veut filer la métaphore, la machine ne rêve donc pas, elle pense. Et quand le terme penser est lâché, on peut alors se demander si ce n’est pas l’intelligence artificielle qui arrive à grand pas pour remplacer l’humain, ce sera l’objet du prochain épisode de ce dossier!
Biblio
- http://neuralnetworksanddeeplearning.com/ : Une sorte de livre en ligne pour vraiment rentrer dans le sujet!
- http://www.iro.umontreal.ca/~bengioy/dlbook/intro.html : le seul bouquin a ma connaissance à l’époque de ce dossier sur le sujet à ce jour (pas lu en entier)
- http://www.ted.com/talks/fei_fei_li_how_we_re_teaching_computers_to_understand_pictures : La vidéo de FeiFei li dont je parle dans le dossier
- https://gigaom.com/2015/07/27/interview-with-stephen-wolfram-on-ai-and-the-future/ : Mr Wolfram nous parle d’AI
- E. Musk : « we should be very careful about artificial intelligence » : Elon Musk sur l’AI
- http://googleresearch.blogspot.fr/2015/06/inceptionism-going-deeper-into-neural.html : Le fameux article de Google sur les rêves
- http://research.microsoft.com/pubs/209355/DeepLearning-NowPublishing-Vol7-SIG-039.pdf : Un document de Microsoft research très complet sur le sujet













J’aurais aimé avoir plus de détails sur les reseaux neuronaux mais cela a quand même été bien
Mais j’irais peut être fourrer dans les sources fournies